
Deep Learning Preliminary knowledge(4):Calculus

导数和微分
导数的计算是所有深度学习优化算法的关键步骤。 在深度学习中,我们通常选择对于模型参数可微的损失函数。简而言之,对于每个参数, 如果我们把这个参数增加或减少一个无穷小的量,可以知道损失会以多快的速度增加或减少.
导数的定义
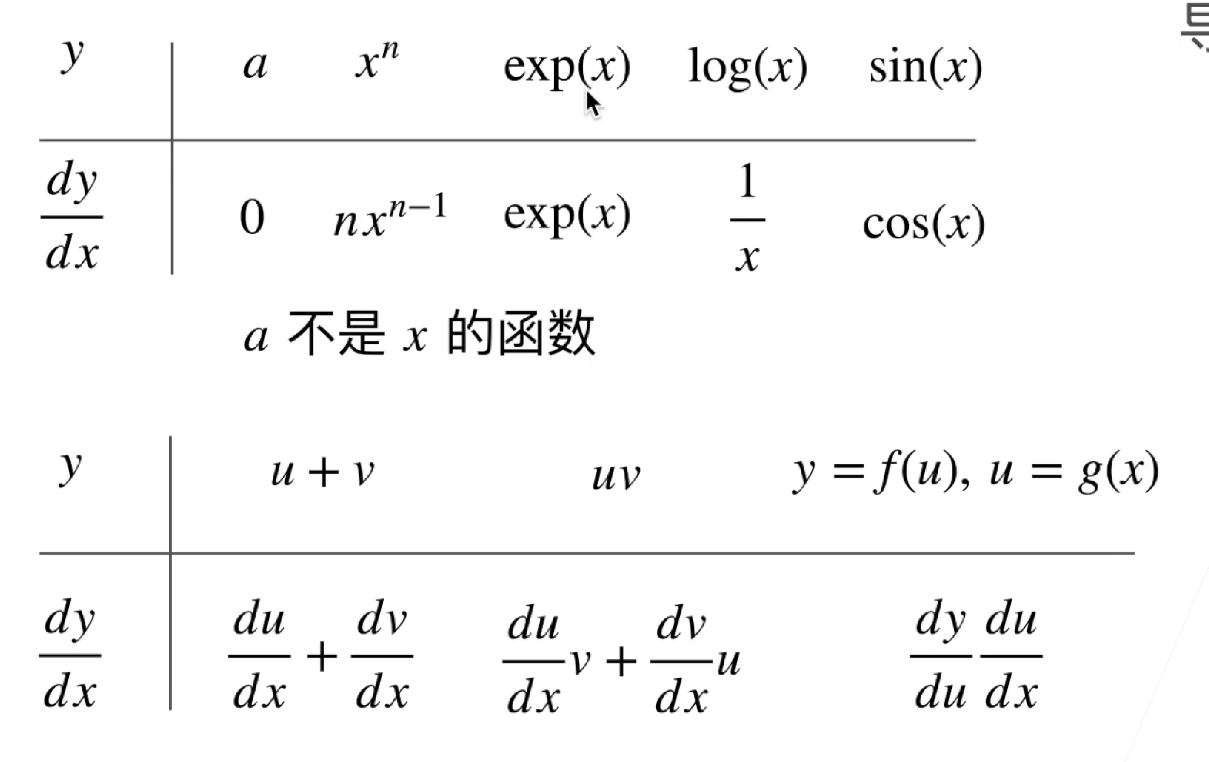
偏导数
定义:一个多变量的函数(或称多元函数),对其中一个变量(导数)微分,而保持其他变量恒定。
这个在深度学习中时非常常见的,函数通常依赖许多变量,可以通过偏导数的方法来看看每一个变量对函数的影响。
一般地,函数f(x1,...,xn)在点(a1,...,an)关于xi的偏导数定义为:
当对某一个参数求偏导时,其他参数都看成常数来处理。
梯度
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
将导数拓展到向量
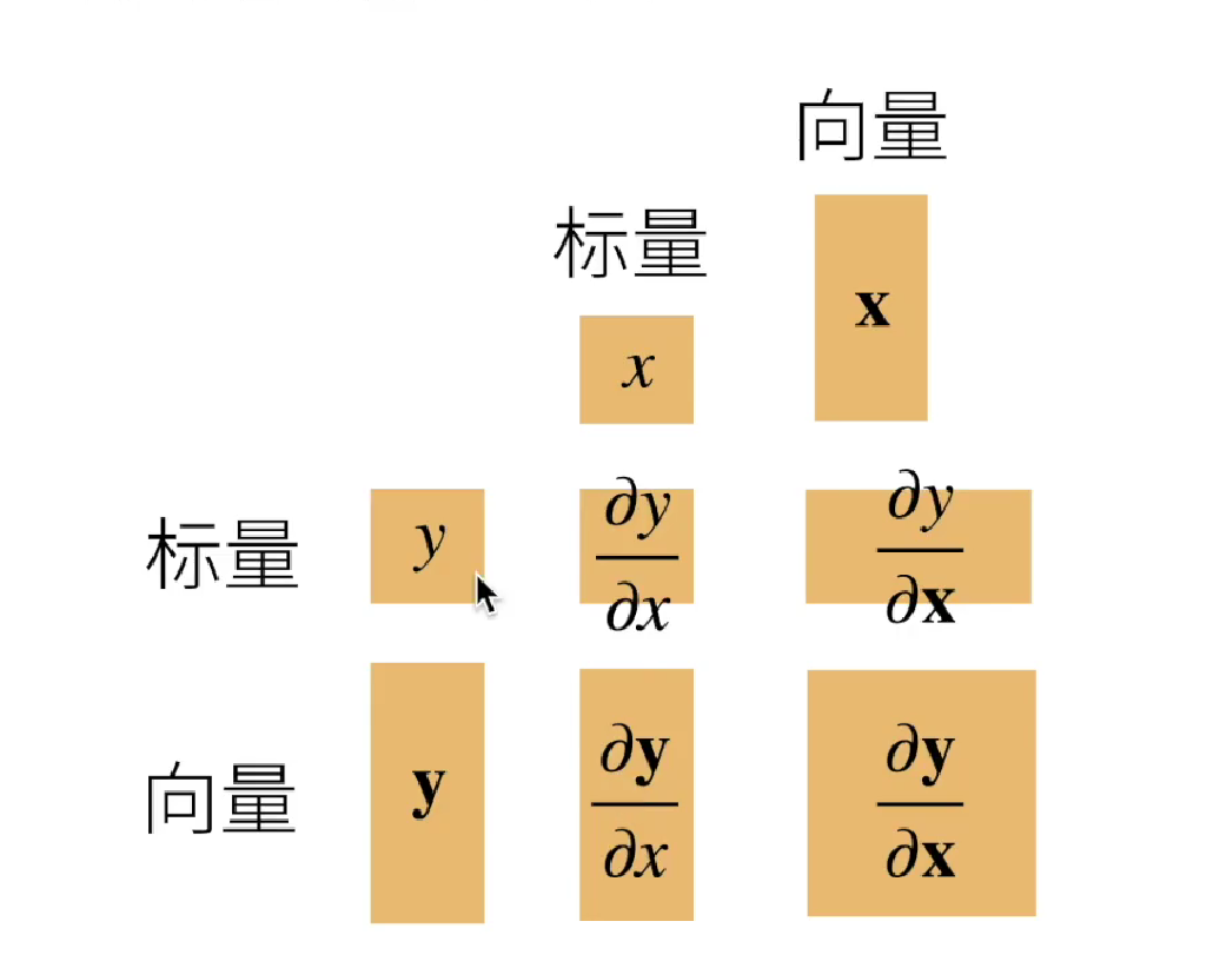
下面来详细说一下这几种情况。
1、当 y 为标量,x为列向量时
其实也很简单,看成是一个有一列的标量对列向量求偏导。那么每一个标量y对x求偏导,得到的就是一个行向量。一共有m个变量,所以得到的是 m * n的矩阵。这个也叫做分子布局。 
关于矩阵求导、分子布局、分母布局,详细可以看这篇文章 hero
链式法则
但是,现实生活中,函数不可能是单一变量,通常是复合的,难以用上面的公式进行求解。这时候就需要用到链式法则了。
标量
当函数
举例,例如
首先,咱们可以看出来是
那么结果为
向量
首先看一下标量对向量的链式求导
假设最终优化的目标z是个标量,
那么就结果为
假设
首先,咱们分析一下,
那么z对求w偏导就是
这个其实是上面的向量求偏导公式
最后
在这两天学习深度学习里面的数学部分中,我发现和我在学校高数课上学的不一样,是一种什么感觉呢?就是感觉自己好像学过,但是又搞不懂是怎么回事。
高数书让我们进行微分、求偏导的都是一个函数表达式,而深度学习里面却是一个向量/矩阵。
那么如何理解向量呢?
其实向量就是把那些函数表达式里面的未知数的系数提取出来,形成一个数组,这就是向量。
矩阵也是如此,把未知数的系数提取出来,形成一个二维数组。
由于还没有学习线性代数,理解比较浅显。只是为了解决 在学习 深度学习过程中,由向量/矩阵引起的困惑。感兴趣的可以看一下下面这两个文章。 向量的本质问答 矩阵的本质
- Title: Deep Learning Preliminary knowledge(4):Calculus
- Author: StarHui
- Created at : 2023-06-17 10:07:43
- Updated at : 2023-11-05 22:34:58
- Link: https://renyuhui0415.github.io/post/Calculus.html
- License: This work is licensed under CC BY-NC-SA 4.0.