
Deep Learning Preliminary knowledge(2):Data Preprocess

介绍
数据预处理是说 现在有现实世界的数据,怎么把它读取进来,通过机器学习的方法能够处理。 下面讲解一下如何使用pandas预处理原始数据,并将原始数据转化为张量的步骤。
读取数据集
由于咱们没有数据集,所以咱们先手动创建一个数据集,并存储在CSV(逗号分隔值)文件 ../data/house_tiny.csv中 来进行下面操作,如有数据集可越过此步骤。
1 | import os |
1 | # 如果没有安装pandas,只需取消对以下行的注释来安装pandas |
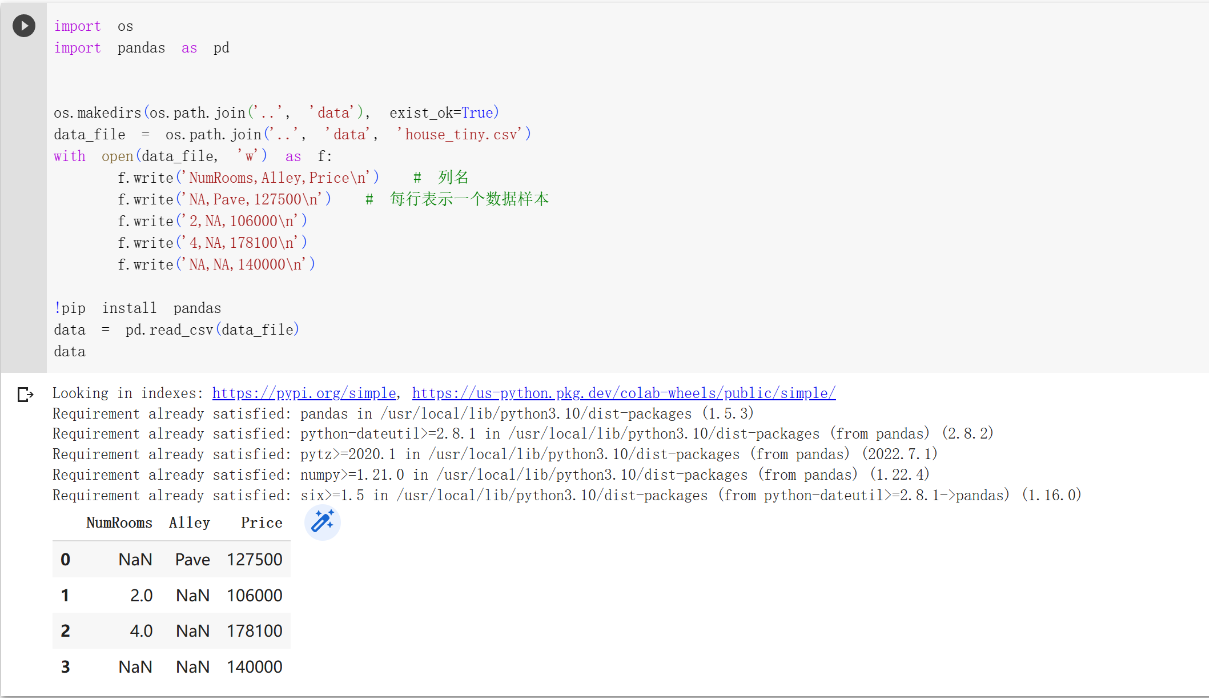
处理缺失值
可以看到,"NaN"表示缺失值。为了处理缺失值,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值,所以咱们只考虑插值法。 首先咱们先切片的方式把数据分为输入(input)、输出(output),输入为数据的前两列,输出为数据的最后一列。然后咱们把输入里面的NaN值用同一列的均值替换。
1 | inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] #前两列为input,最后一列为output |
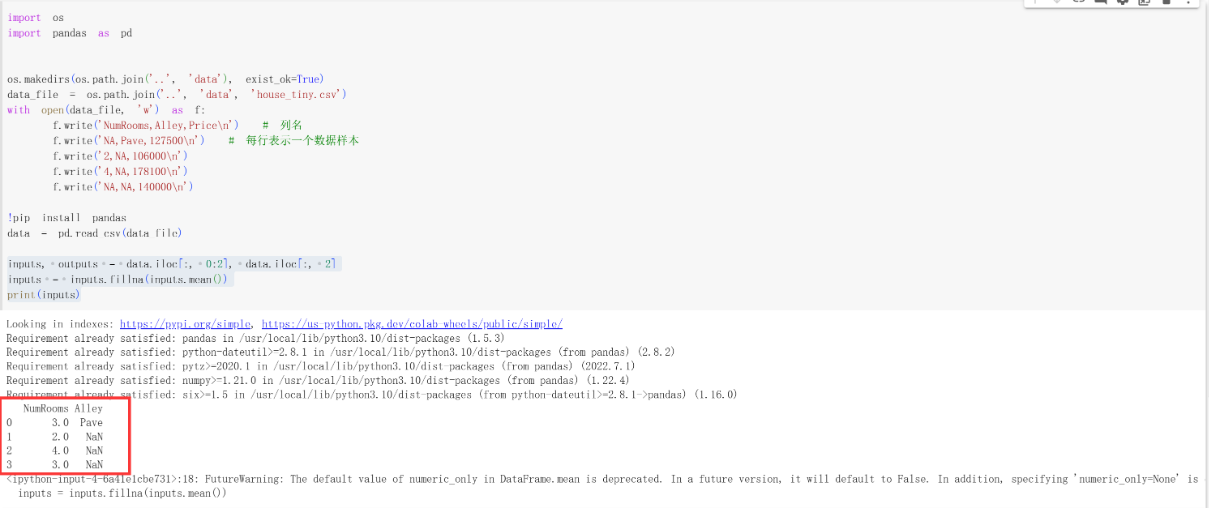
但是input里面有些值不是数字怎么办呢?是字符串。咱们还需要把字符串变为数值,方便后面处理。 首先把所有出现的不同数值(字符串等数据类型)变成一个特征,通过get_dummies函数建几类。如果之前的值是其中的一个类的话,那么那个类里面就为1,否则为0.
1 | inputs = pd.get_dummies(inputs, dummy_na=True) |
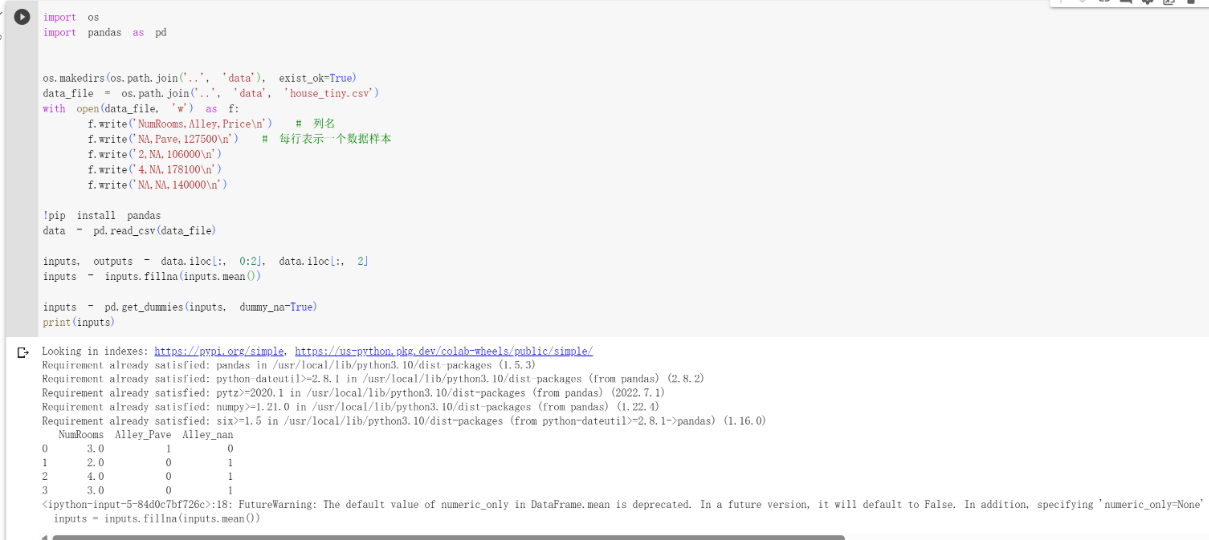
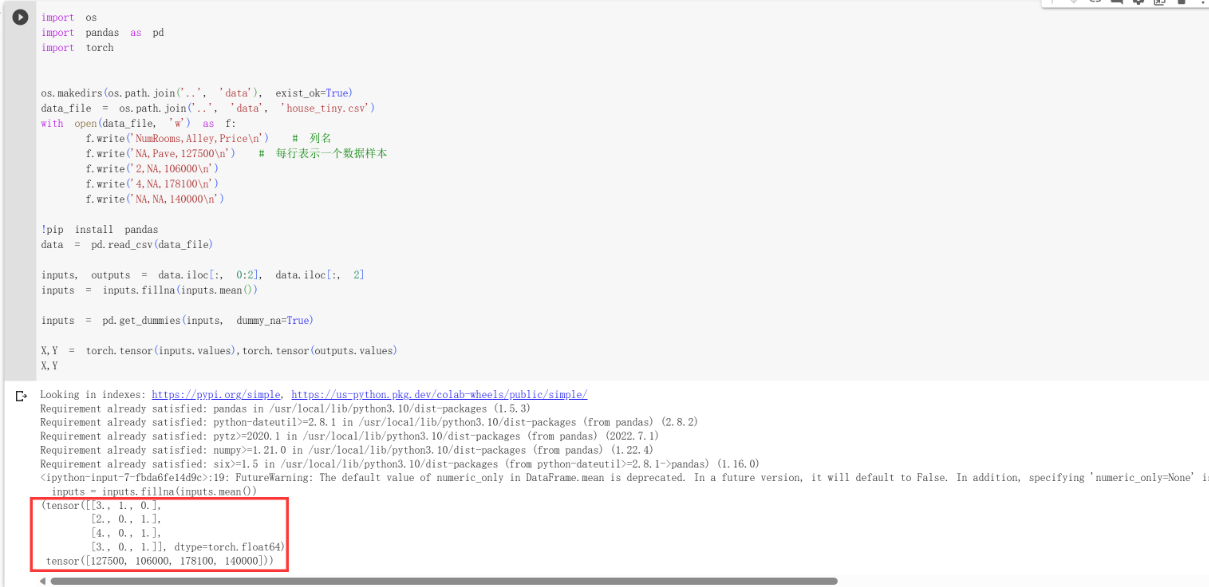
转换为张量格式
现在所有的数据都是数值类型了,可以转换为张量格式了。
1 | import torch |
- Title: Deep Learning Preliminary knowledge(2):Data Preprocess
- Author: StarHui
- Created at : 2023-06-13 16:56:00
- Updated at : 2023-11-05 22:20:23
- Link: https://renyuhui0415.github.io/post/data_preprocess.html
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments