Configuring yolov5 Environment Of Windows Error Collection

前言
前一段时间打了一个数据科学竞赛,发现自己的不足之处,并未对深度学习进行下一步学习,而是去实操,练习一下应用能力。
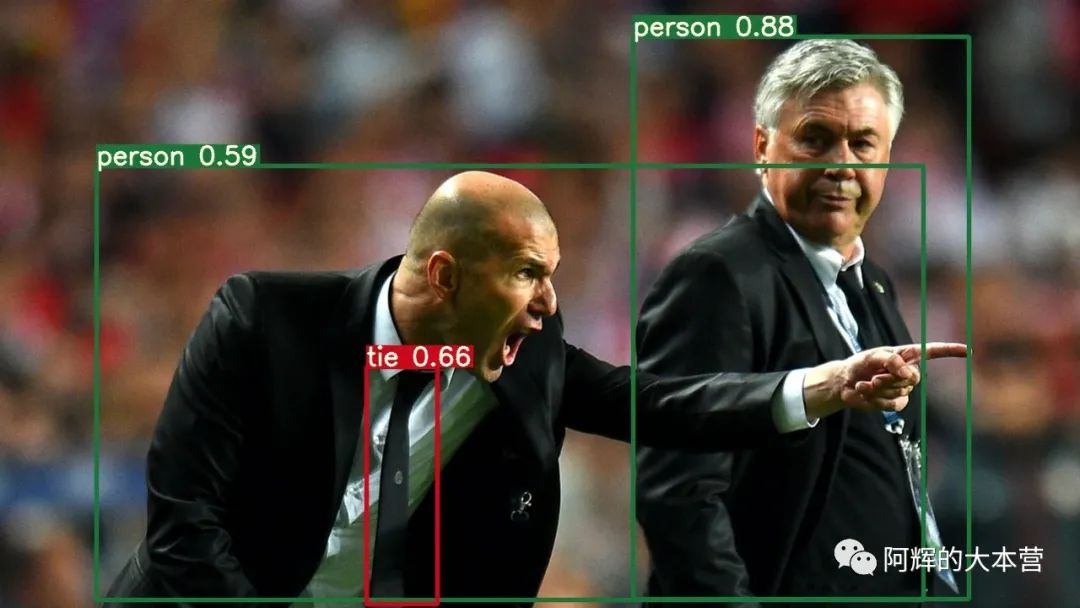
这一次,参加另外一个比赛,做一个智能垃圾桶。
所谓智能,就是能够识别垃圾类别,放到对应的垃圾桶里面。核心是目标检测算法,这里采用的是yolov5。接下来讲一下配置环境后,运行yolov5测试所遇到的报错,帮助大家避雷。
配置环境
配置环境,我没有什么可说的,网上教程一抓一大把,这里我推荐的是 史上最详细yolov5环境配置搭建+配置所需文件.
需要注意的是,看好自己电脑是否有英伟达显卡,没有的话,pytorch需要按照CPU版本的。
运行yolo报错
本人环境
- conda 23.7.4
- PyCharm 2023.2.1 (Professional Edition)
- Python 3.8.18
- Pytorch 2.0.1+cpu
AttributeError: Can't get attribute 'SPPF' on <module 'models.common' from 'E:\yolov5\models\common.py'>
配置好环境后,使用 python detect.py 测试是否部署成功,结果出现了第一个报错。
报错内容如下
1 | Traceback (most recent call last): |
报错原因:无法在名为models.common的模块中找到SPPF属性引起的。
首先在网上搜索了一下,发现都是在 models/common.py 里面添加 SPPF 类,可是这样治标不治本啊,为什么要添加这个类?
然后,我在Github yolov5的issues里面查了一下,发现有一个优质解答
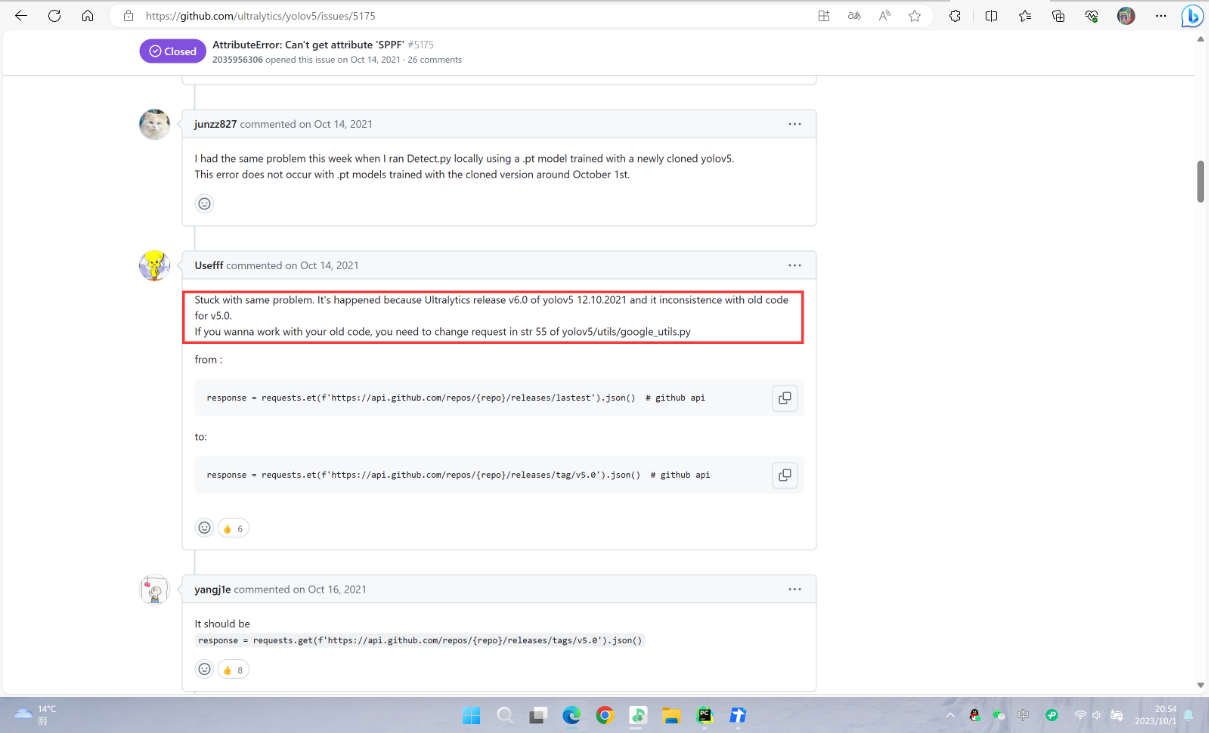
大致原因就是 Ultralytics 发布了yolo新版本,与v5不兼容,想要用v5的代码需要修改一个地方。
修改文件路径 : yolov5/utils/google_utils.py 第25行
原来代码为
1 | response = requests.get(f'https://api.github.com/repos/{repo}/releases/lastest').json() # github api |
可以看到,默认获取是最新版本的,咱们需要改为v5的即可
1 | response = requests.get(f'https://api.github.com/repos/{repo}/releases/tag/v5.0').json() # github api |
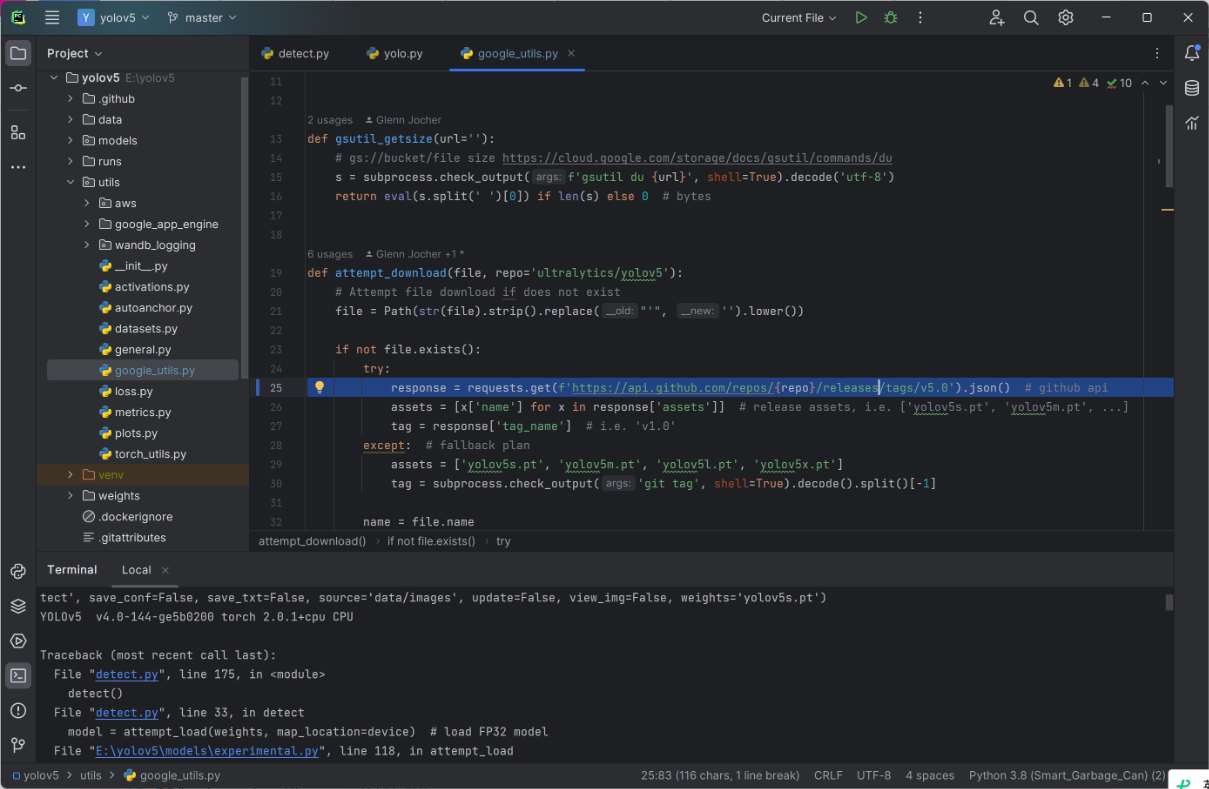
AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
紧接着,第二个报错就出现了。
1 | image 1/2 E:\yolov5\data\images\bus.jpg: Traceback (most recent call last): |
该错误的原因是使用了一个过时的API。
在早期版本的PyTorch中,使用’recompute_scale_factor’属性来重新计算缩放因子。然而,在较新的版本中,API已经更新,’recompute_scale_factor’属性被删除了,因此代码会引发上述错误。
而网络上普遍的解决办法都是修改torch源码,这样是不正确的,因为这个是底层,在其他地方也有调用,可能会导致一些未知的错误出现。
所以我们应该采取另外一种方案,加一个判断语句。
修改文件路径:yolov5.py 第124行
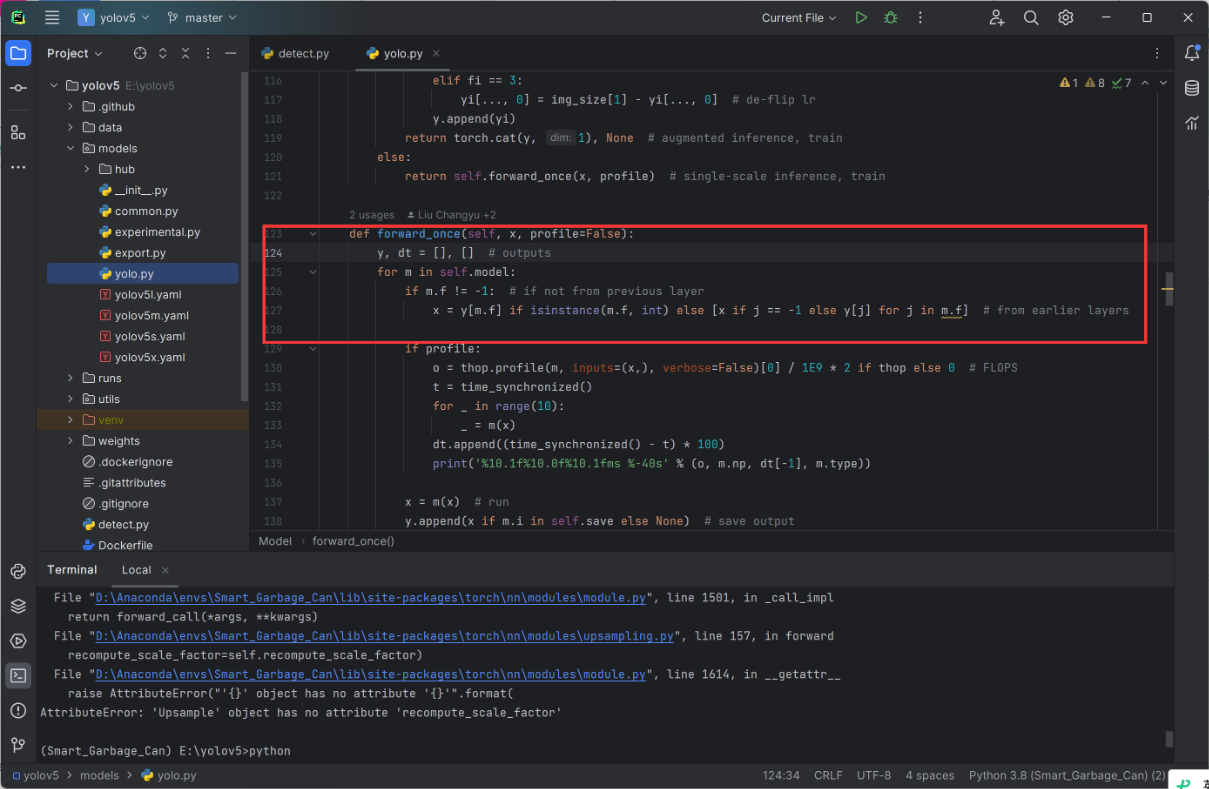
修改代码如下
1 | def forward_once(self, x, profile=False): |
其实就是一个判断语句,为了适应新版本的要求。
isinstance(m, nn.Upsample) 用于判断变量 m 是否是 nn.Upsample 类的实例。如果是,则执行下一行代码 m.recompute_scale_factor = None,将 recompute_scale_factor 属性设置为 None,以适应新版本PyTorch的要求。
测试结果
经过上面的修改后,在PyCharm的控制台输入 python detect.py 即可成功运行。运行成功后,会在 yolov5文件夹下出现一个 runs文件夹,在里面查看即可。
查看路径 yolov5/runs/detect/exp

写在最后
当出现报错后,在网上搜索后,不要盲目跟着 CSDN 的解决方法去做。而是应该先去知道为什么报错,然后再去解决它。现在网上很多博客都是为了解决这个问题而解决,从未想过为什么会出现这个报错。盲目修改底层源码后,会导致后面可能会出现从未见过的报错,尽量不要轻易修改。
后面会讲一下如何做一个智能垃圾桶(程序方面),敬请期待哈。
- Title: Configuring yolov5 Environment Of Windows Error Collection
- Author: StarHui
- Created at : 2023-10-01 21:31:13
- Updated at : 2023-11-06 21:57:57
- Link: https://renyuhui0415.github.io/post/Configuring-yolov5-Environment-Of-Windows-Error-Collection.html
- License: This work is licensed under CC BY-NC-SA 4.0.