
Linear Regression Experiment

前言
学完之后,感觉有点不过瘾,所以在网上找了一个csv文件来试试线性回归
波士顿房价数据集
先下载到本地后,接下来就开始吧。
上传数据
由于我用的是colab,所以接下来就讲解colab如何导入cvs文件以及读取。
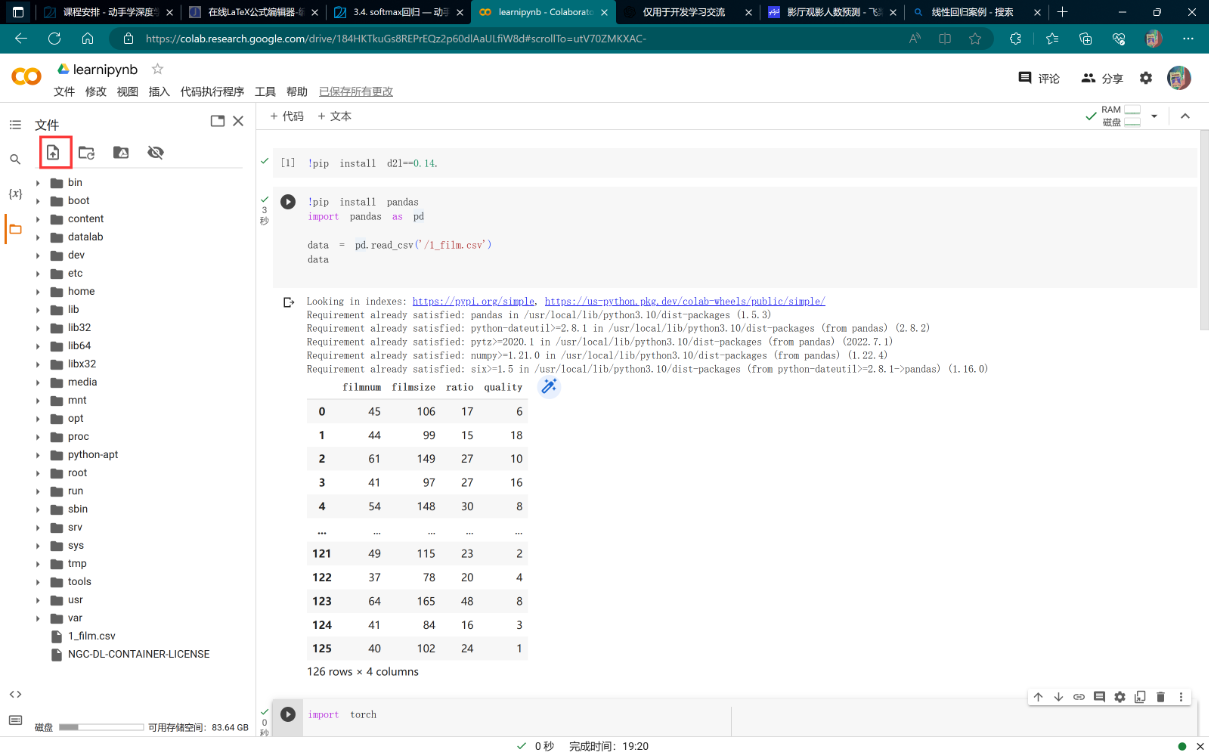
点击上传文件,上传后找到该文件,右键复制路径
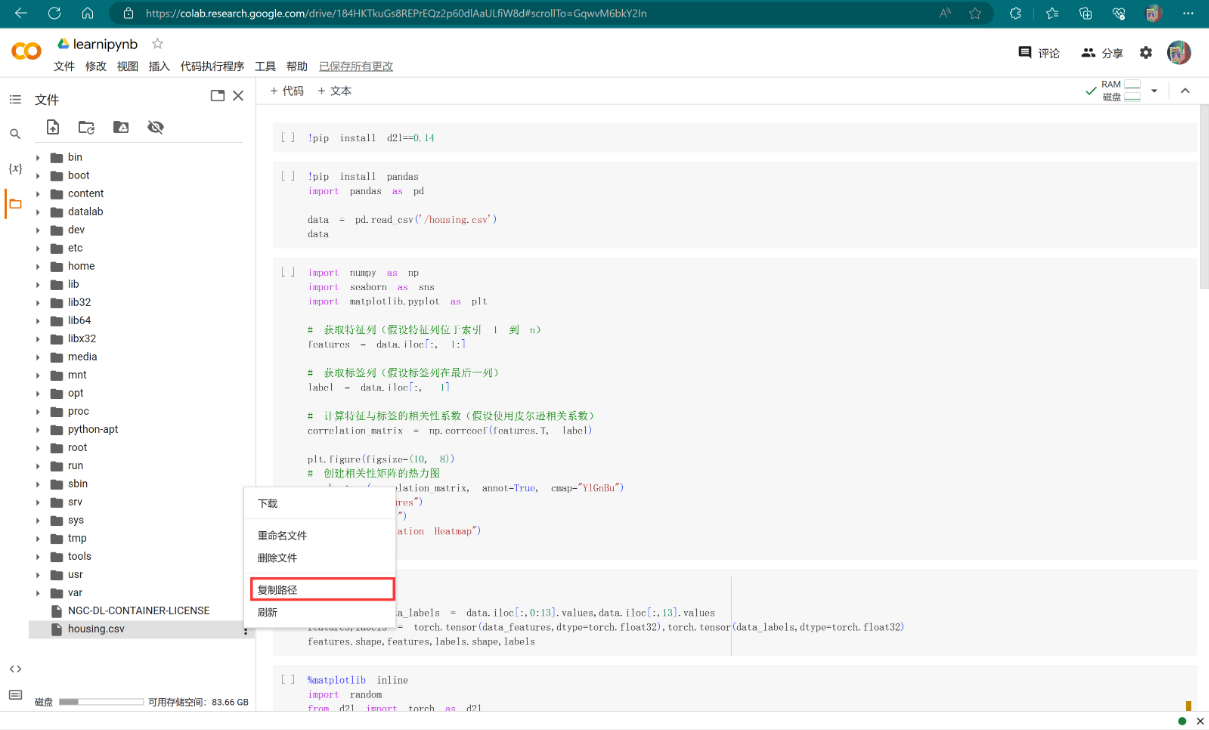
读取数据
1 | !pip install pandas |
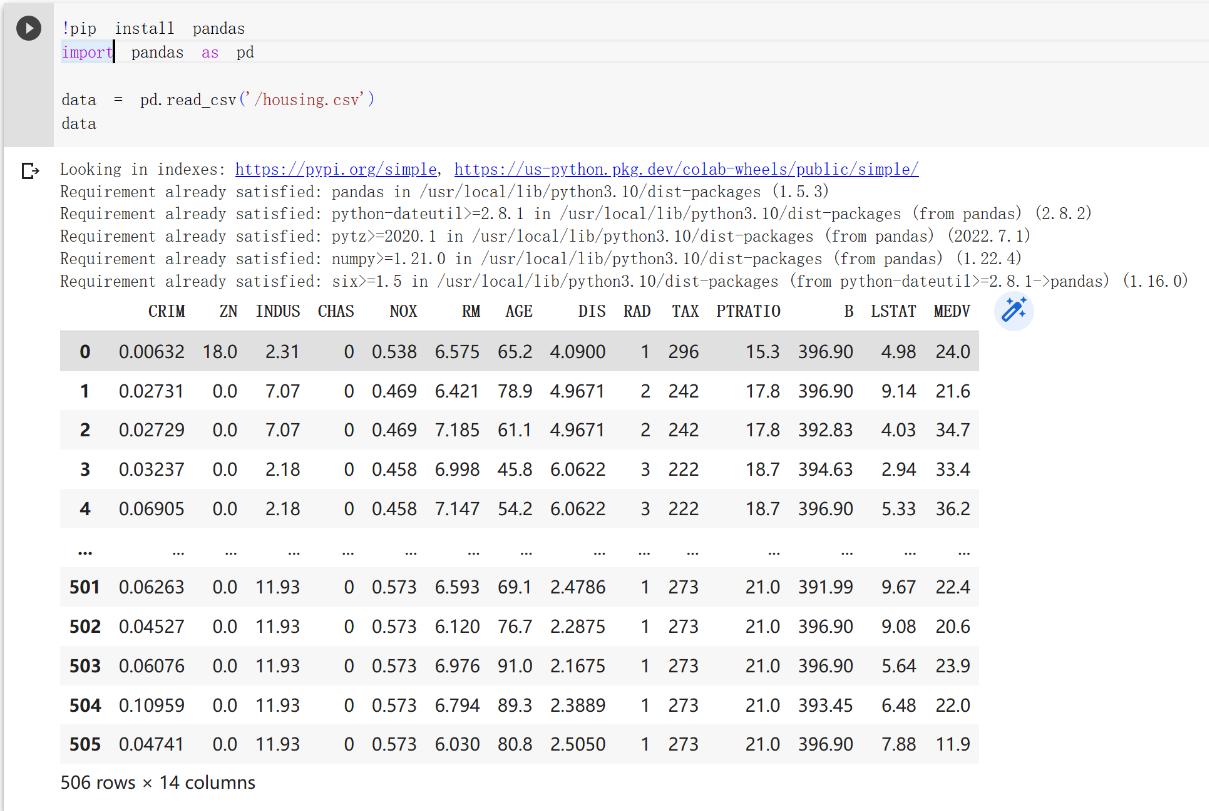
数据预处理
数据清洗
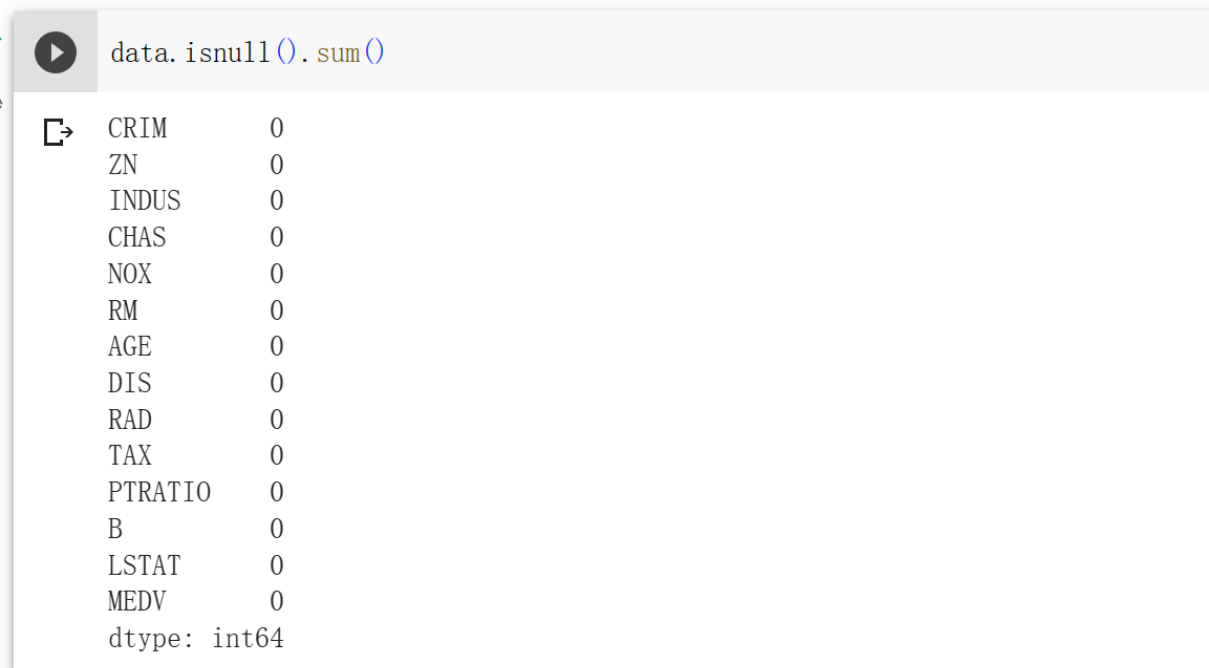
首先看一下有没有空值,可以使用isnull函数查看
1 | data.isnull().sum() #sum函数累加统计 |
以下是各字段的解释,图片来自网络截屏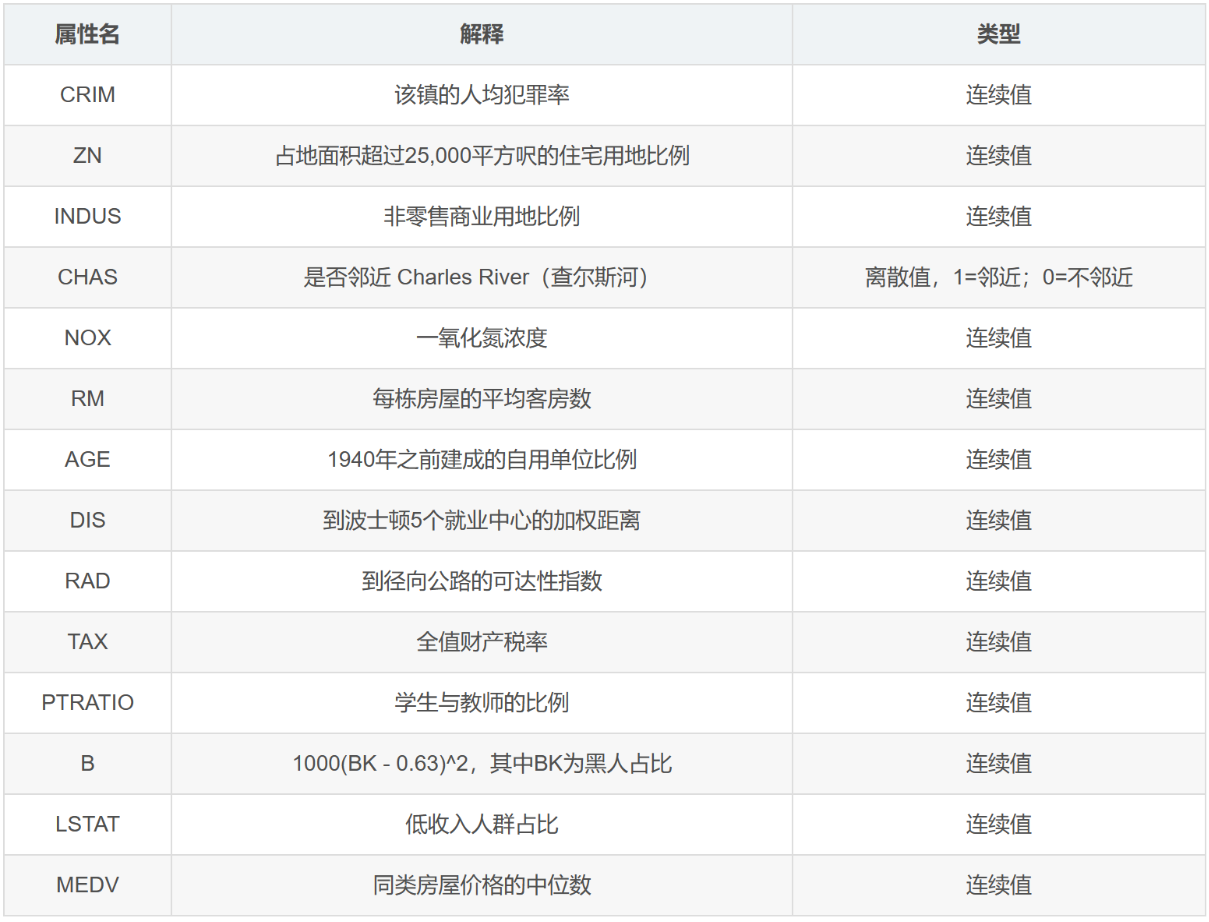
接下来看看是否异常值,使用 describe函数
1 | data.describe() |
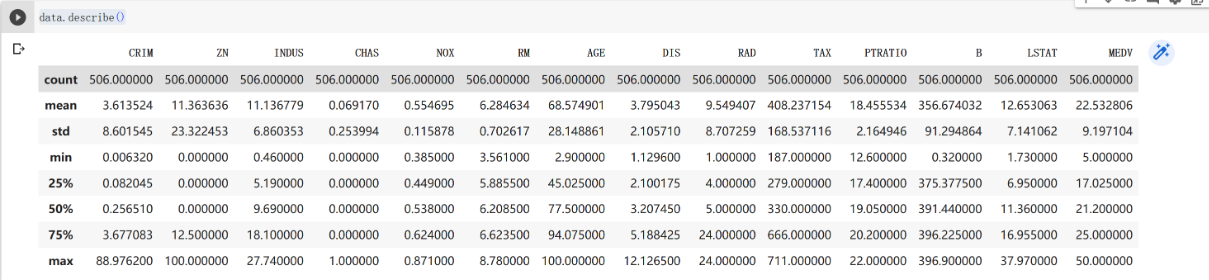
可以看出每一行的值都是正常的,没有异常值.
最后看一下有没有重复项。
1 | data.duplicated() #检查每一行是否重复性,没有返回false,有返回true |
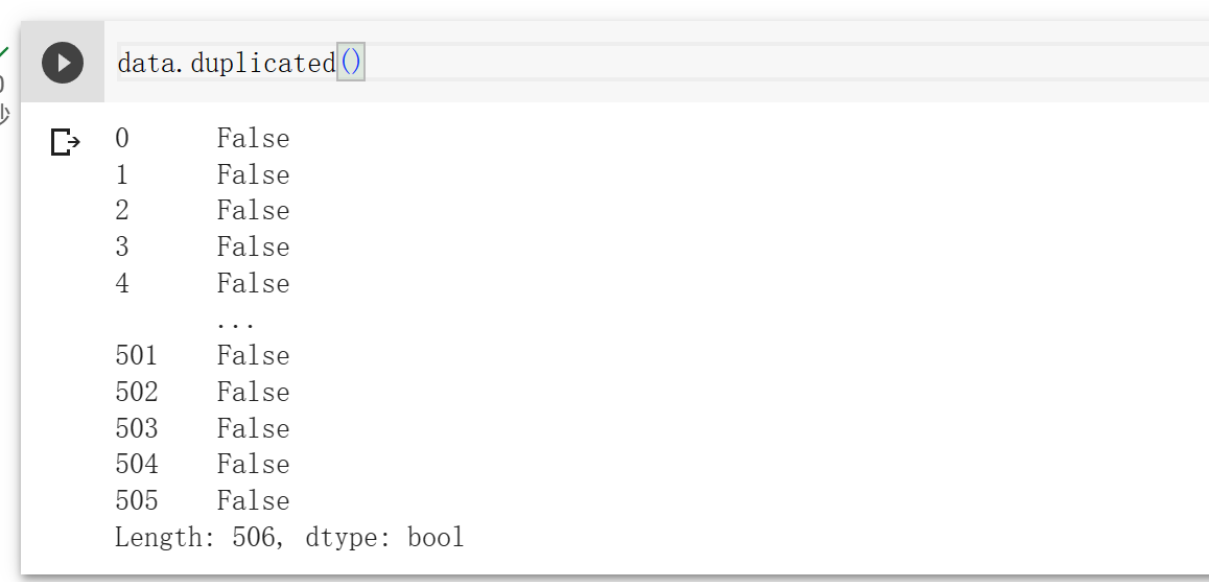
特征选择
由于参数太多,可能会影响后面模型的准确性,所以选择把不相关的特征删除。
就是删除相关系数小于0.5的特征,只保留大于等于0.5的特征。
首先计算每一个特征与标签的相关系数。
1 | correlation_matrix = data.corr() # 计算相关系数矩阵 |
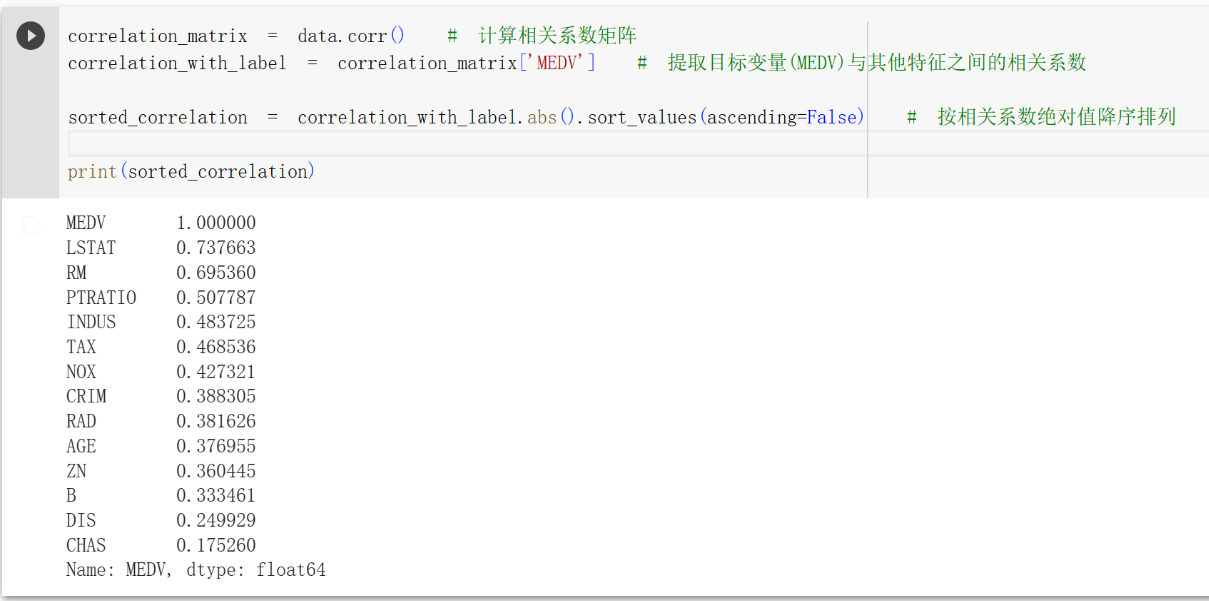
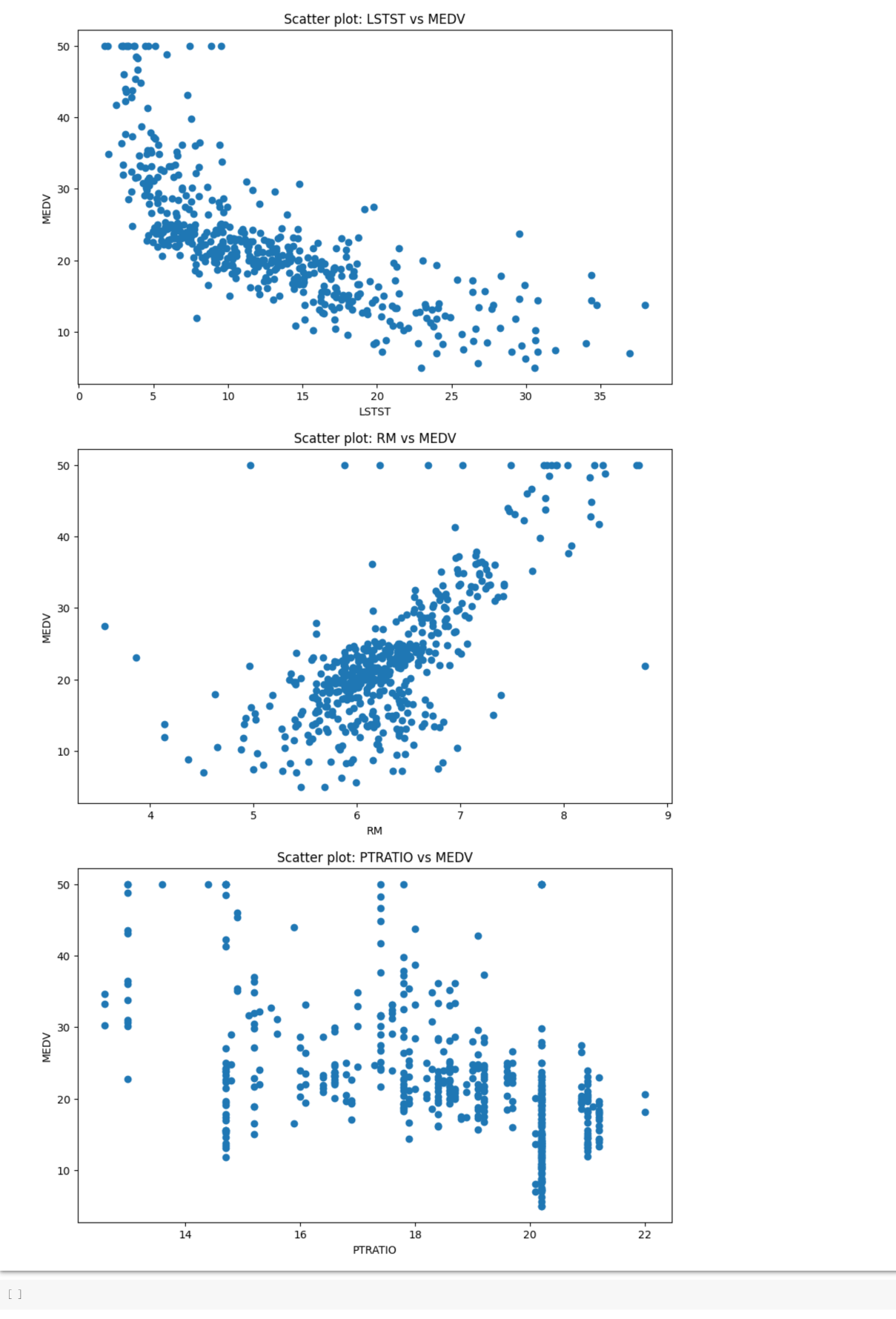
MEDV是本身,所以相关系数为1,我不知道怎么删除这个。除此之外,可以发现LSTAT、RM、PTRATIO 相关系数大于等于0.5了。
接下来画出这三个与标签的散点图
1 | import matplotlib.pyplot as plt |
此时的 data 是一个Pandas 数据帧(DataFrame)对象,可以使用type()函数看一下
此时由于里面有的是字符串型,这里就需要用到咱们之前讲过的数据预处理里面的 处理缺失值。让字符串那一列变成一个特征,这样就变成了0、1.
接下来把data切片转化为 features(矩阵)、lables(向量)
1 | import torch |

特征放缩
特征放缩是什么?为什么要进行特征放缩呢?先来看一张图
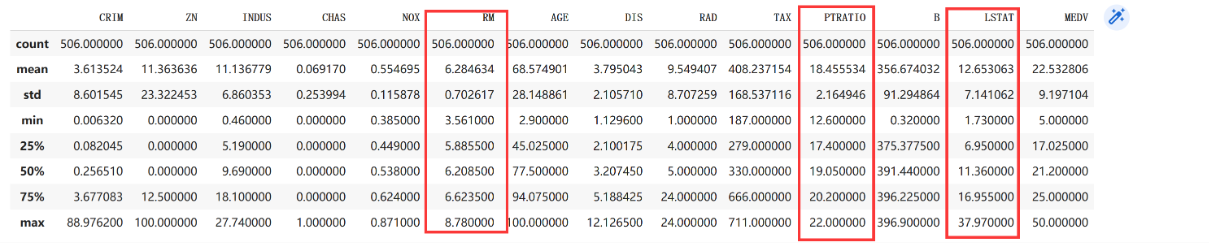
这三个是咱们的保留下来的特征,从图中咱们可以发现,这三个特征的平均值、最小值、最大值差的有点多。这样的差异会导致某些特征在模型训练中的权重更新过程中起主导作用,使得模型过于关注数值较大的特征,而忽略了其他特征的贡献。
通过特征放缩,可以将所有特征的数值调整到相似的尺度,减少数值差异对模型训练的影响,使得模型更加平衡地考虑不同特征的重要性。
而特征放缩有常用的有三个,标准化、Min-Max归一化方法、Min-Max归一化方法.
数据的特征放缩
这里采用的是Min-Max归一化方法。
将原始值减去最小值,并将差值除以最大值与最小值之间的差,从而获得新的归一化值。
1 | from sklearn.preprocessing import MinMaxScaler |

可以发现、特征、标签都被归一化0~1之间了。
读取数据集
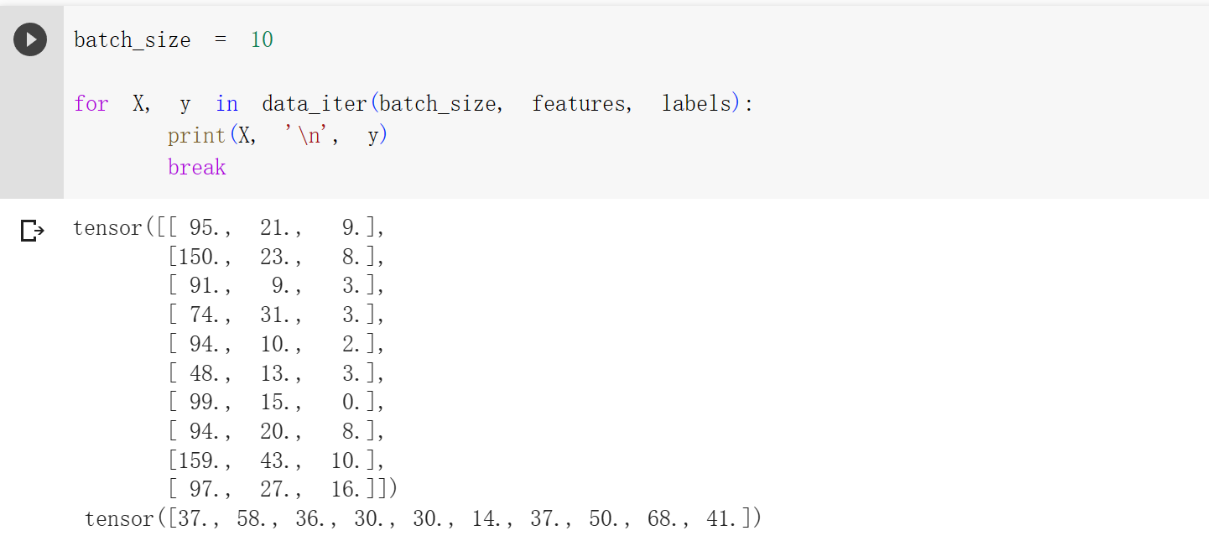
原理:创建下标索引数组,然后原地打乱。最后通过 for循环来选择 batch_size个下标(不一定,有可能 i + batch_size越界,然后取num_example ),最后通过这些下标来返回batch_size 个特征、标签
1 | def data_iter(batch_size,features,labels): |
1 | batch_size = 10 |
初始化模型参数
还是w随机,b设置为0
1 | w = torch.normal(0, 0.01, size=(3,1), requires_grad=True) |
定义模型
由于这个是简单的线性回归,
1 | def linreg(X, w, b): |
定义损失函数
还是均分损失函数
1 | def squared_loss(y_hat, y): |
1 | def sgd(params, lr, batch_size): #params是所有参数w、b的列表;lr为学习率、baatch_size为样本数量 |
1 | lr = 0.03 # 学习率 |
1 | def mse_score(y_hat, y): |

写在最后
其实这个和前面李沐老师讲的差不多,只不过多了一些数据处理操作。由于没有学过pandas,所以其中数据操作比较粗糙,敬请谅解!!!
- Title: Linear Regression Experiment
- Author: StarHui
- Created at : 2023-06-21 21:01:17
- Updated at : 2023-11-06 20:05:37
- Link: https://renyuhui0415.github.io/post/Linear_Regression_Experiment.html
- License: This work is licensed under CC BY-NC-SA 4.0.